Migrating from Flurry
Overview
If you’re reading this, congrats on considering making the switch from Flurry Analytics to Mixpanel 🎊 This migration guide is to take you through our best practice recommendations on how to set up in Mixpanel, what the differences are from Flurry, and how to get your teams up and running quickly in Mixpanel.
A migration primarily consists of 4 phases:
- Technical migration of data → Data audit, Live data cutover, Historical data import (optional)
- Change management migration of end users → Champion identification, User interviews, Team by team specific trainings, Ensuring adoption for each team
- Data governance and implementation optimization → Improving / Implementing data governance processes, Identifying missing or incorrect data, Optimizing workflows for adding/editing data
- Ongoing success planning → Building a product analytics practice
From a technical perspective, the migration process is relatively straightforward. If you have an engineer with access to your data and the ability to write code/transforms to send data to new destinations, this can be done in a single sprint (1-3 weeks).
From an end user perspective, Mixpanel’s UX is simpler and easier to learn. The largest hurdle is copying over key saved reports, dashboards, etc. that the team is familiar with in your current tool and teaching them how to rebuild these in Mixpanel. We recommend doing this process in detail for each team, showing them how to recreate key analyses side-by-side in Mixpanel. You can then leverage your team champions to force multiply your adoption efforts.
When going through this migration, there is no better time to audit your own data and reports to only migrate what matters. Most data and reporting is stale after some time anyways, prioritize the data and reports your team uses every day for their Top 10 key questions. These can be easily copied over.
Data Differences
Data Model Differences
Both Mixpanel and Flurry Analytics collect event-based behavioral data about your users. Events (opens in a new tab) are commonly expressed as JSON which represent the name of the user action, the ID of the user, the time at which the action took place, and all associated metadata. Events are immutable, and represent data at the time of which an action takes place.
{
"event": "Signup",
"properties":
{
"time": 1618716477000,
"distinct_id": "91304156-cafc-4673-a237-623d1129c801",
"$insert_id": "29fc2962-6d9c-455d-95ad-95b84f09b9e4",
"Referred by": "Friend",
"URL": "mixpanel.com/signup"
}
}In addition to events, Mixpanel supports an additional type of data that Flurry does not. This data is known as user profiles (opens in a new tab), which represents dimensional data that is always updated to the most recent value for a user. User data allows you to segment your reporting by both historical point-in-time data as well as real-time dimensional data about your users.
{
"$distinct_id": "13793",
"$set":
{
"name": "Robert"
}
}We also support additional data for extending your use cases with Mixpanel:
- Group profiles (opens in a new tab): Used with our Group Analytics product add-on to allow you to pivot quickly between users and other entities in your analysis. A common use case is for a B2B company to pivot between analyzing users and analyzing accounts.
- Lookup tables (opens in a new tab): For event data which was already sent, you can use these to extend the data already sent into Mixpanel. A common use case is taking an identifier like a transaction ID, item ID, etc. and using lookup tables to enrich the data with additional information like the amount, category, etc. from your data warehouse.
ID Management Differences
Mixpanel supports stitching user behaviour pre-login (e.g. traffic from your website, docs, blog) and post-login (once the user has signed up). This helps answer questions like:
- What % of site visitors end signing up?
- How much of my Purchase revenue can I attribute to a particular campaign?
- What is the conversion rate of reading a particular blog post → signing up?
This system is called ID Merge. If using our Web / Mobile SDKs or a CDP, once your user signs up or logs in, call .identify(<user_id>). Any events prior to calling .identify are considered anonymous events. Mixpanel's SDKs will generate a $device_id to associate these events to the same anonymous user. By calling .identify(<user_id>) when a user signs up or logs in, you're telling Mixpanel that $device_id belongs to a known user with ID user_id. Under the hood, Mixpanel will stitch the event streams of those users together. This works even if a user has multiple anonymous sessions (eg: on desktop and mobile). As long as you always call .identify when the user logs in, all of that activity will be stitched together.
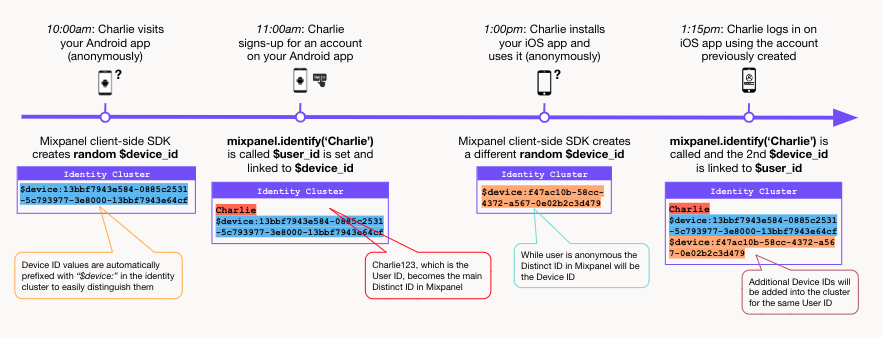
Anonymous users on Flurry are also identified based on their device IDs. Similarly, users can be identified using the Flurry.setUserId method to capture the user ID. The key difference here is though: Flurry does not support the stitching of user behaviour pre-login and post. That means in the Charlie example above, we will not be able to match Charlie across the Android or iOS devices. User IDs are set as user properties only in Flurry on the device level (opens in a new tab), and not applied to multiple devices (opens in a new tab). As a consequence, it can be difficult to do user data reconciliation between Mixpanel and Flurry because users may be overstated on Flurry.
Data Capture Differences
Two key areas where Mixpanel differs from Flurry in data capture:
- In Mixpanel, we have no limits on the events we capture. Whereas in Flurry, no more than 1000 events will be captured in a given session. If you capture more than 1000, the first to be captured are lost. (opens in a new tab)
- In Mixpanel, sessions are virtual events that you can configure, and apply the changes retroactively. Whereas in Flurry, if the app pauses or moves to the background for more than 10 seconds, the next time the app runs, Flurry will automatically create a new session and end the prior session (opens in a new tab).
Historical Backfill of Existing Data
Given the above identity management and data structure differences between Mixpanel and Flurry, we recommend starting afresh because you will not be able to easily reconcile the users and data across the two platforms.
If you must import historical Flurry data for reference purposes, we strongly recommend loading historical data into a separate Mixpanel project.
To backfill data, we recommend the following approaches:
- If you have a data warehouse, we recommend exporting your raw data from Flurry (opens in a new tab) to that data warehouse, and then use our data warehouse connector or Import API (opens in a new tab) to import to Mixpanel
- If you do not have a data warehouse: you can export your raw data from Flurry and leverage our helper function (opens in a new tab) to move it into MIxpanel
Sending Live Data to Mixpanel
Data Audit
We’ve found from experience that <20% of the data in a product analytics tool is used for 80%+ of the queries. This is especially true the longer you have been using a tool - over time teams add more and more tracking for new events and properties, and without strong data governance practices, you will inevitably have some messy data in your current analytics tool(s).
In the spirit of making sense of the mess, we recommend that if you’re starting afresh with a new implementation, you should at least do a quick audit to understand the key reports, events, and properties that your end users have been using in Flurry. No queries in the past 30 days? These events and properties have probably gone stale - there is low value and high effort in bringing them to Mixpanel, so cut them from your import and do not migrate the existing tracking.
Given that Flurry Analytics is sunsetting March 15 2024, this audit step might be fine for now. Once you have completed the process of implementing Mixpanel, you can then set aside more time to properly assess the current state of your data trust and where you need to address datta issues to gain adoption. We will go over data governance best practices further down this guide once you’ve successfully migrated your end users.
Identifying Your Implementation Method
Mixpanel accepts event data from a variety of different sources. Choose your implementation method first and then you can follow the below steps for sending data to Mixpanel.
We support the following data collection mechanisms:
- Client-side SDKs & Server-side SDKs: Simply replace Flurry code calls to track events with Mixpanel calls instead
- Customer Data Platforms (CDPs) like Segment (opens in a new tab): Go into your CDP settings to add Mixpanel as a destination, and point your data stream to Mixpanel
- Warehouse Connectors: If you have data already in Snowflake, BigQuery, Redshift, and Databricks, you can set up recurring syncs from your data warehouse.
- Import API: Point your event ingestion pipeline to Mixpanel’s robust API (opens in a new tab) for data ingestion
- Reverse ETL (RETL) tools like Census (opens in a new tab): Go into your RETL settings to add Mixpanel as a destination, and point your syncs to Mixpanel
Below, we go through how you can update your Flurry SDKs to Mixpanel SDKs.
Client-side SDKs
Mixpanel and Flurry client side SDKs have similar developer facing APIs. This makes it fairly easy to “find and replace” embedded Flurry calls and swap them for Mixpanel calls.
This section will detail the iOS Swift SDKs (for the sake of brevity), although both analytics platforms have fairly uniform tracking APIs for other SDKs.
Flurry iOS Docs: https://github.com/flurry/flurry-ios-sdk/tree/master?tab=readme-ov-file#examples (opens in a new tab)
Mixpanel iOS Docs: /docs/tracking-methods/sdks/swift
Installing the Mixpanel SDK
Before getting started, initialize the Mixpanel SDK according to the directions here
Initialization
Flurry:
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {
let sb = FlurrySessionBuilder()
.build(logLevel: FlurryLogLevel.all)
.build(crashReportingEnabled: true)
.build(appVersion: "1.0")
.build(iapReportingEnabled: true)
Flurry.startSession(apiKey: "YOUR_API_KEY", sessionBuilder: sb)
return true
}Mixpanel:
import Mixpanel
func application(_ application: UIApplication,
didFinishLaunchingWithOptions launchOptions: [NSObject: AnyObject]?) -> Bool {
...
// Replace with your Project Token
Mixpanel.initialize(token: "Your Token", trackAutomaticEvents: false)
...
}Events
Flurry’s logEvent() method:
// Standard events
Flurry.log(eventName: "Event", parameters: ["Key": "Value"])
// Timed events
Flurry.log(eventName: "Event", parameters: ["Key": "Value"], timed: true)
Flurry.endTimedEvent(eventName: "Event", parameters: ["Key": "Value"])Mixpanel’s track() method:
Mixpanel.mainInstance().track(event: "Event",
properties:["Key": "Value"])
// Timed events
Mixpanel.mainInstance().time(event: "Event")
Mixpanel.mainInstance().track(event: "Event")Identity Management
Flurry’s setUserId() method:
Flurry.set(userId:"user_id")Mixpanel’s identify() method:
Mixpanel.mainInstance().identify(distinctId: "user_id");User Properties
Flurry’s setUserProperties() method:
Flurry.set(userId: "USER_ID")
Flurry.set(gender: "f")Mixpanel’s people.set() method:
Mixpanel.mainInstance().people.set(properties: [ "userID":"USER_ID", "gender":"f")Note: identify() should be called at some point in each user’s session to propagate people methods
Not sure where to start or need help?
If you're unsure how you currently track data, or might want to consider tracking data differently as you migrate to Mixpanel, we recommend starting here (opens in a new tab).
Change Management Migration of End Users
Once you have live data in Mixpanel, the next step is to start helping your existing end users of Flurry learn to use Mixpanel.
To give everyone a foundation of how to use Mixpanel, we recommend checking our our tutorials here.
We’ve found also that the best way to get end users to adopt a new tool is to appoint a champion to help drive change. A great champion would be someone on your team who is data savvy, and can help the team assess the the top used reports in Flurry, and run targeted trainings where you work with end users to re-build these reports side by side in Mixpanel.
Data governance and implementation optimization
Once you’ve migrated your data have started to enable end users on Mixpanel, this is a good time to take a pause and do a retrospective of the change management, and do a deeper assessment of the current state of your data and identify if there are data issues that will help you further gain adoption. This might mean needing to implement new datasets or improve existing tracking to increase the number of use cases which can be explored by end users. You can read more around our recommended approach and questions to ask yourself here (opens in a new tab).
Ongoing success planning
After you’ve successfully migrated both your tracking and end users over to Mixpanel, we recommend you focus on longer term goals like:
- Improving Data Governance → Creating scaleable processes and strategies for managing data at scale
- Optimizing Analysis → Helping end users analyze data for more use cases, faster via training and documentation
- Building a Product Analytics Practice → Cultural change to be a self-serve, data democratized organization
You can read more about how we do this here (opens in a new tab).
Was this page useful?